# 了解一下基础知识点
- Object.create
- new 原理
- import.meta
- sort
- indexOf
- 柯里化
- 防抖
- 节流
- 原生 XMLRequest
- 面试题:请求 10 张图片,并发量为 3,一张请求成功后如何挑选另外一张去继续请求
- 如何取消一个 promise?
- 图片转 base64
- 上传前预览图片
- 模块化
- localStorage 安全问题
- 非匿名自执行函数的函数名只读
- 手写 Event 类
- 请实现_.get函数
- co 原理
- koa 原理
- koa 中间件的 next()方法报错了怎么办
- Koa 与 Express
- JS 作用域,作用域链,执行上下文,执行上下文栈,AO,VO
- 说一下 this
- 闭包
- 小程序与 H5 的区别
- 小程序与普通网页开发的区别
- 小程序原理
- 小程序的生命周期
- 小程序打包怎么实现的呢?
- replace 方法
- 数据类型
- 栈内存和堆内存
- function.length
- requestAnimationFrame
- 如何对小数取整
- 位运算优缺点
- 为什么通常在发送数据埋点请求的时候使用的是 1x1 像素的透明 gif 图片?
- input 搜索如何防抖,如何处理中文输入
- JavaScript 有几种类型的值?你能画一下他们的内存图吗?
- 什么是堆?什么是栈?它们之间有什么区别和联系?
- 内部属性 [[Class]] 是什么?
- undefined 与 undeclared 的区别?
- null 和 undefined 的区别?
- 如何获取安全的 undefined 值?
- JavaScript 原型,原型链? 有什么特点?
- 在 js 中不同进制数字的表示方式
- js 中整数的安全范围是多少?
- typeof NaN 的结果是什么?
- isNaN 和 Number.isNaN 函数的区别?
- Array 构造函数只有一个参数值时的表现?
- 其他值到字符串的转换规则?
- 其他值到数字值的转换规则?
- 其他值到布尔类型的值的转换规则?
- {} 和 [] 的 valueOf 和 toString 的结果是什么?
- 什么是假值对象?
- ~ 操作符的作用?
- 解析字符串中的数字和将字符串强制类型转换为数字的返回结果都是数字,它们之间的区别是什么?
- + 操作符什么时候用于字符串的拼接?
- 什么情况下会发生布尔值的隐式强制类型转换?
- || 和 && 操作符的返回值?
- Symbol 值的强制类型转换?
- 如何将字符串转化为数字,例如 '12.3b'?
- 如何将浮点数点左边的数每三位添加一个逗号,如 12000000.11 转化为『12,000,000.11』?
- 如何实现数组的随机排序?
- javascript 创建对象的几种方式?
- JavaScript 继承的几种实现方式?
- 寄生式组合继承的实现?
- Javascript 的作用域链?
- 谈谈 This 对象的理解
- eval 是做什么的?
- 什么是 DOM 和 BOM?
- 写一个通用的事件侦听器函数。
- 事件是什么?IE 与火狐的事件机制有什么区别? 如何阻止冒泡?
- 三种事件模型是什么?
- 事件委托是什么?
- 什么是闭包,为什么要用它?
- javascript 代码中的 "use strict"; 是什么意思 ? 使用它区别是什么?
# Object.create
作用:Object.create 可以用来创建一个纯净的空对象,这个对象没有原型,如Object.create(null)
原理:实际上是创建一个空对象,将空对象的proto指向第一个参数
// 比如Object.create(null)的实现
const obj = {}
obj.__proto__ = null
2
3
# new 原理
new 的过程其实不复杂,直接看 MDN 上的描述
new 关键字会进行如下的操作:
- 创建一个空的简单 JavaScript 对象(即{});
- 为步骤 1 新创建的对象添加属性proto,将该属性链接至构造函数的原型对象 ;
- 将步骤 1 新创建的对象作为 this 的上下文 ;
- 如果该函数没有返回对象,则返回 this。
const _new = function(fn, ...args) {
/* 第一步相当于
const obj = {}
obj.__proto__ = fn.prototype
*/
const obj = Object.create(fn.prototype)
const ret = fn.apply(obj, args)
return ret instanceof Object ? ret : obj
}
2
3
4
5
6
7
8
9
# import.meta
import.meta 对象由一个关键字"import",一个点符号和一个 meta 属性名组成。通常情况下"import."是作为一个属性访问的上下文,但是在这里"import"不是一个真正的对象。
import.meta 对象是由 ECMAScript 实现的,它带有一个 null 的原型对象。这个对象可以扩展,并且它的属性都是可写,可配置和可枚举的。
# sort
深入浅出 JavaScript 的 Array.prototype.sort 排序算法 (opens new window)
sort() 方法用原地算法 (opens new window)对数组的元素进行排序,并返回数组。
默认排序顺序是在将元素转换为字符串,然后比较它们的 UTF-16 代码单元值序列时构建的
由于它取决于具体实现,因此无法保证排序的时间和空间复杂性。
在计算机科学中,原地算法是一种不使用辅助数据结构转换输入的算法。但是,允许为辅助变量提供少量额外的存储空间。当算法执行时,输入通常被输出覆盖。原地算法只通过替换或者交换元素来更新它的输入序列。没有就位的算法有时被称为不就位或不就位。
如果没有指明 compareFunction ,那么元素会按照转换为的字符串的诸个字符的 Unicode 位点进行排序。例如 "Banana" 会被排列到 "cherry" 之前。当数字按由小到大排序时,9 出现在 80 之前,但因为(没有指明 compareFunction),比较的数字会先被转换为字符串,所以在 Unicode 顺序上 "80" 要比 "9" 要靠前。
ECMA 规范中并没有明确定义用哪种排序方式实现 sort 方法
# 各个浏览器有自己的实现方式
| 浏览器 | 使用的 JavaScript 引擎 | 排序算法 |
|---|---|---|
| Google Chrome | V8 | 插入排序和快速排序 |
| Mozilla Firefox | SpiderMonkey | 归并排序 |
| Safari | Nitro(JavaScriptCore ) | 归并排序和桶排序 |
| Microsoft Edge 和 IE(9+) | Chakra | 快速排序 |
V8 引擎的一段注释
// In-place QuickSort algorithm.
// For short (length <= 10) arrays, insertion sort is used for efficiency.
2
Google Chrome 对 sort 做了特殊处理,对于长度 <= 10 的数组使用的是插入排序(稳定排序算法) ,>10 的数组使用的是快速排序。快速排序是不稳定的排序算法。
# 各种算法的对比
| 排序类型 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 快速排序 | O(nlogn) | O(nlogn) | O(n²) | O(nlogn) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 插入排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 桶排序 | O(n+k) | O(n+k) | O(n²) | O(n+k) | 不稳定 |
# indexOf
indexOf()方法返回在数组中可以找到一个给定元素的第一个索引,如果不存在,则返回-1。通过查看ECMA 最新规范 (opens new window)indexOf 的实现,可知它是线性遍历查找字符串,时间复杂度是 O(n)
# 柯里化
# 已知传入函数的参数个数
function create_curry(func, ...args) {
let argity = func.length // 获取函数参数个数
args = args || []
return function() {
args = [...args, ...arguments]
if (args.length >= argity) {
// 如果参数个数上限了则执行函数
return func.apply(this, args)
}
return create_curry(func, ...args)
}
}
// 使用举例
function check(reg, targetString) {
return reg.test(targetString)
}
var _check = create_curry(check)
var checkPhone = _check(/^1[34578]\d{9}$/)
// console.log("checkPhone('183888888')", checkPhone('13415055850'))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 面试题:不知道函数参数的个数
我们先稍微分析一下:上面的柯里化我们知道函数参数个数,所以我们可以知道调用函数的时机
但是这道面试题不知道参数个数,那么是无法通过参数的多少来判断函数执行的时机
我们最终只能得到一个函数,只要这个函数执行我们就能获得结果
但我们不想手动执行,那么只能考虑在某个时间点偷偷的调用函数,得到结果
这个时间点,就是 JS 引擎给我们打印结果的时机,当我们打印一个函数时,JS 引擎会自动调用 toString 函数
我们只需要重写 toString 函数既可
新版 Chorme 中
console.log的实现方式不太一样,没有调用 toString,我们可以通过alert(add(1)(2)(3))来查看结果
function add(...args) {
args = args || []
function adder() {
args = [...args, ...arguments]
return adder
}
// console.log的时候,会将内容转为字符串,在这个时机会调用toString函数
adder.toString = function() {
return args.reduce((cur, res) => (res += cur))
}
return adder
}
// add(1)(2)(3) = 6;
// add(1, 2, 3)(4) = 10;
// add(1)(2)(3)(4)(5) = 15;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 防抖
# 延迟防抖(延迟时间结束触发)
const debounce_delay = function(func, wait) {
let timer = null
return function() {
clearTimeout(timer)
timer = setTimeout(() => {
func.apply(this, arguments)
}, wait)
}
}
2
3
4
5
6
7
8
9
# 立即防抖(周期时间开始时触发)
const debounce_now = function(func, wait) {
let timer = null
return function() {
clearTimeout(timer) //注意这里timer并不会变为undefined或者null啥的
let call_now = !timer
timer = setTimeout(() => {
timer = null
}, wait)
if (call_now) func.apply(this, arguments)
}
}
2
3
4
5
6
7
8
9
10
11
# 二合一版本
const _debounce = function(func, wait, immediate = false) {
let timer = null
return function() {
clearTimeout(timer)
if (immediate) {
let call_now = !timer
timer = setTimeout(() => {
timer = null
}, wait)
if (call_now) func.apply(this, arguments)
} else {
timer = setTimeout(() => {
func.apply(this, arguments)
}, wait)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 节流
# 节流定时器版本
const throttle__setTimeout = function(func, time) {
let can_run = true
return function() {
if (!can_run) return
can_run = false
setTimeout(() => {
func.apply(this, arguments)
can_run = true
}, time)
}
}
2
3
4
5
6
7
8
9
10
11
# 节流时间戳版本
const throttle__timeStamp = function(func, time) {
let pre = 0
return function() {
let now = Date.now()
if (now - pre < time) return
func.apply(this, arguments)
pre = now
}
}
2
3
4
5
6
7
8
9
# 原生 XMLRequest
注意:兼容性问题
- 如果不需要通过请求头发送数据,send(null)要将 null 传入
- 为了确保跨浏览器兼容性,建议将 onreadystatechange 事件处理程序放在 open 方法前面
- setRequestHeader 必须写在 open 和 send 方法之间
const $ = {
get(url, cb) {
const xhr = new XMLHttpRequest()
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
cb.call(this, xhr.responseText)
}
}
xhr.open('get', url)
xhr.send(null)
}
}
2
3
4
5
6
7
8
9
10
11
12
# 怎么终止请求?
可以手动调用 xhr.abort()方法取消请求
# 进度条实现?
xhr.upload.onprogess = function(e) {
e.total //总大小
e.loaded //已经上传的大小
}
xhr.onprogress = function(e) {
e.position //表示已经接收的字节数
e.totalSize //表示根据Content-Length响应头确定的预期字节数
}
2
3
4
5
6
7
8
# 面试题:请求 10 张图片,并发量为 3,一张请求成功后如何挑选另外一张去继续请求
分析:利用 Promise.race 可以实现
- Promise.race 只要有一个 promise 对象进入 FulFilled 或者 Rejected 状态的话,就会继续进行后面的处理
- 首先,先挑选 3 张图片去作为一个 promises
- 通过 Promise.race 并发请求
- 当其中一个请求到达的时候会触发回调,将到达的 promise 替换成新的 promise,继续并发请求
const urls = [
'https://www.kkkk1000.com../.vuepress/public/images/getImgData/getImgDatadata.jpg',
'https://www.kkkk1000.com../.vuepress/public/images/getImgData/gray.gif',
'https://www.kkkk1000.com../.vuepress/public/images/getImgData/Particle.gif',
'https://www.kkkk1000.com../.vuepress/public/images/getImgData/arithmetic.png',
'https://www.kkkk1000.com../.vuepress/public/images/getImgData/arithmetic2.gif',
'https://www.kkkk1000.com../.vuepress/public/images/getImgData/getImgDataError.jpg',
'https://www.kkkk1000.com../.vuepress/public/images/getImgData/arithmetic.gif',
'https://www.kkkk1000.com../.vuepress/public/images/wxQrCode2.png'
]
/**
* 加载对应url的图片
* @param {*} src
*/
function loadOneImg(src) {
return new Promise((resolve, reject) => {
try {
const img = new Image()
img.src = src
img.onload = function() {
console.log('url:', src, '的图片加载成功')
resolve()
}
img.onerror = function() {
reject()
}
} catch (e) {
reject()
}
})
}
/**
* @param {*} limit 并发量
*/
function loadImgs(limit) {
let copy = urls.slice() // 复制一份
let promises = []
// 先组成一个promises数组,promises数量为limit,返回index
// index是promises数组中每个promise对应的位置
promises = copy
.splice(0, limit)
.map((url, index) => loadOneImg(url).then(() => index))
let p = Promise.race(promises) //第一次并发请求
for (let i = 0; i < copy.length; i++) {
//遍历剩余的url
// 每次并发请求由p控制
p = p.then((index) => {
// 上一次并发请求成功后,将数组中对应的promise替换成新的promise
promises[index] = loadOneImg(copy[i]).then(() => index)
// 重新并发请求
return Promise.race(promises)
})
}
}
// 放到浏览器控制台执行
loadImgs(3)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 如何取消一个 promise?
分析:借助 Promise.race 的特性
- 我们自定义一个 mypromise,将 mypromise,promise 两个一起用 race 发送
- 这样我们调用 mypromise 的 resolve 或者 reject 函数的时候就能够在 promise 请求成功前拦截
function wrapper(promise) {
const wrap = {} // 存储自定义promise的resolve和reject事件,以便随时调用
const p = new Promise((resolve, reject) => {
wrap.resolve = resolve
wrap.reject = reject
})
wrap.promise = Promise.race([p, promise]) //存储并发请求
return wrap
}
// 测试
const testp = new Promise((resolve) => {
setTimeout(() => {
resolve('success')
}, 2000)
})
const p = wrapper(testp)
p.promise.then((res) => {
console.log(res)
})
p.resolve('stop http') // 改变自定义promise的状态,阻止另外一个请求
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 图片转 base64
const imgURL = './01.png' //图片链接
// 图片转base64
function toBase64(image) {
var canvas = document.createElement('canvas')
canvas.width = image.width
canvas.height = image.height
const ctx = canvas.getContext('2d')
ctx.drawImage(image, 0, 0, image.width, image.height) //将图片画到画布上
const ext = image.src.substring(image.src.lastIndexOf('.') + 1).toLowerCase() //图片后缀png
const dataURL = canvas.toDataURL('image/' + ext) //将画布转为指定的base64格式,这里是image/png
return dataURL
}
const image = new Image()
image.src = imgURL
image.onload = function() {
const base64 = toBase64(image)
console.log(base64)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 上传前预览图片
<input type="file" name="" id="fileInput" />
<script>
// 上传图片前预览
const oInput = document.getElementById('fileInput')
oInput.addEventListener('change', function(e) {
console.log(e.target.files)
const file = e.target.files[0] //file 对象
if (file) {
// base64读取文件对象
const reader = new FileReader()
reader.readAsDataURL(file) //将文件读取为dataURL(base64)
reader.onload = function(e) {
console.log(e.target.result) //获取到base64格式字符串
// 将该字符串放到对应的img标签即可预览
}
}
})
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 模块化
# 方案一:立即执行函数(IFFE)
;(function(window) {
window.test = function() {}
})(window)
2
3
# 方案二:AMD
define(['./a', './b'], function(a, b) {
// 加载完毕的回调
a.do()
b.do()
})
2
3
4
5
# 方案三:CMD
define(function(require, exports, module) {
// 延迟加载
var a = require('./a')
a.do()
})
2
3
4
5
# 方案四:CommonJS
// module是node特有的一个对象
module.exports = {
a: 1
}
// 基本实现
module = {
id: '',
exports: {}
}
var exports = module.exports
var load = function(module) {
// 导出的东西
var a = 1
module.exports = a
return module.exports
}
// 然后当执行require的时候去找到对应id的module
// 将要使用的东西用IFFE包装一下,over
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# localStorage 安全问题
localStorage 存在安全问题,封装溢出逻辑的 localStorage,主要是要知道溢出抛出的错误事件名称(QuotaExceededError)
localStorage.set = (key, value) => {
try {
localStorage.setItem(key, value)
} catch (err) {
console.log(err)
if (err.name === 'QuotaExceededError') {
console.log('已超出5MB的存储大小!')
localStorage.clear()
localStorage.setItem(key, value)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
封装过期时间的 localStorage
class LocalStorage {
/**
* @param {Number} exp 过期时间
*/
constructor(exp) {
this.exp = exp
this._items = {}
}
setItem(key, val) {
this._items[key] = {
value: val,
time: Date.now()
}
}
getItem(key) {
const item = this._items[key]
if (Date.now() - item.time > this.exp) {
console.log('expires')
} else {
return item.value
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 非匿名自执行函数的函数名只读
作用域:执行上下文包含作用域链
作用域,可以理解为执行上下文中声明的变量和作用范围;包括块级作用域和函数作用域
特性:声明提升,函数声明优先于变量声明
在非匿名自执行函数中,函数名是只读状态,无法修改
var b = 10
;(function b() {
b = 20
console.log(b) //function b(){}
})()
console.log(b) //10;
2
3
4
5
6
# 手写 Event 类
function Event() {
this._events = {}
}
// on事件监听
Event.prototype.on = function(type, fn) {
if (!this._events[type]) {
this._events[type] = []
}
this._events[type].push(fn)
}
// off移除监听
Event.prototype.off = function(type, fn) {
if (!this._events[type]) {
return
}
if (!fn) {
// 无指定函数,全部移除
this._events[type] = undefined
return
}
const index = this._events[type].indexOf(fn)
this._events[type].splice(index, 1)
}
// emit触发事件
Event.prototype.emit = function(type) {
if (!this._events[type]) {
return
}
this._events[type].forEach((f) => f())
}
// once只触发一次
Event.prototype.once = function(type, fn) {
const _ = this
const _fn = function() {
_.off(type, _fn)
fn.apply(_, arguments)
}
this.on(type, _fn)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 请实现_.get函数
其函数原型为:_.get(object,path,[defaultValue])
// 例子:
// var object = { 'a': [{ 'b': { 'c': 3 } }] }
// _.get(object, 'a[0].b.c') //=>3
// _.get(object, ['a', '0', 'b', 'c']) //=>3
// _.get(object, 'a.b.c', 'default') //=>default
var _ = {}
_.get = (obj, path, defaultValue) => {
if (defaultValue) return defaultValue
// 将路径字符串转为数组,循环读取对象
if (Object.prototype.toString.call(path) === '[object String]') {
path = path.replace(/\[/g, '.')
path = path.replace(/\]/g, '')
path = path.split('.')
}
let index = 0
while (obj && index < path.length) {
obj = obj[path[index++]]
}
return obj
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# co 原理
co可以让generator函数自动执行,原理是不断调用generator函数的next函数,直到执行完毕,类似async、await函数自动执行,最后返回一个Promise
核心代码:next 函数
/**
* Get the next value in the generator,
* return a promise.
*
* @param {Object} ret
* @return {Promise}
* @api private
*/
// 反复执行调用自己
function next(ret) {
// 检查当前是否为 Generator 函数的最后一步,如果是就返回
if (ret.done) return resolve(ret.value)
// 确保返回值是promise对象。
var value = toPromise.call(ctx, ret.value)
// 使用 then 方法,为返回值加上回调函数,然后通过 onFulfilled 函数再次调用 next 函数。
if (value && isPromise(value)) return value.then(onFulfilled, onRejected)
// 在参数不符合要求的情况下(参数非 Thunk 函数和 Promise 对象),将 Promise 对象的状态改为 rejected,从而终止执行。
return onRejected(
new TypeError(
'You may only yield a function, promise, generator, array, or object, ' +
'but the following object was passed: "' +
String(ret.value) +
'"'
)
)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# koa 原理
洋葱模型的实现主要涉及koa-compose和koa-convert,中间件函数使用Promise串联,next函数返回的是一个Promise,koa-compose通过use函数收集中间件函数,最终会调用compose合并所有中间件后返回的函数,遇到中间件是generator函数,调用koa-convert来转换成Promise,最终是通过co来转换的
核心代码:compose 函数
function compose(middleware) {
// 校验 middleware 是数组,且校验数组中的每一项是函数
if (!Array.isArray(middleware))
throw new TypeError('Middleware stack must be an array!')
for (const fn of middleware) {
if (typeof fn !== 'function')
throw new TypeError('Middleware must be composed of functions!')
}
return function(context, next) {
let index = -1
function dispatch(i) {
// 一个函数不能多次调用
if (i <= index)
return Promise.reject(new Error('next() called multiple times'))
index = i
// 获取中间件函数
let fn = middleware[i]
if (i === middleware.length) fn = next // 当middleware为空时,将next(如果compose有传next函数则让其执行后返回,否则为undefined)赋值给fn
if (!fn) return Promise.resolve() // 如果fn为空,直接 resolve
try {
// fn(context, dispatch.bind(null, i + 1)),首先执行了 fn 函数,同时将 dispatch(i+1) 作为 next 传递到下一次执行
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)))
} catch (err) {
return Promise.reject(err) // fn执行报错捕获
}
}
return dispatch(0)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# koa 中间件的 next()方法报错了怎么办
中间件链错误会由ctx.onerror捕获,该函数会调用this.app.emit('error',err,this),因为koa是继承自Events模块,所以有emit和on等方法,另外可以使用app.on('error',(err)=>{})或者app.onerror=(err)=>{}进行捕获+
# Koa 与 Express
Koa 特点:
基于 Promises 的控制流程
没有回调地狱。
通过 try/catch 更好的处理错误。
无需域。
Koa 非常精简
- 不同于 Connect 和 Express,Koa 不含任何中间件
- 不同于 Express,不提供路由
- 不同于 Express,不提供许多便捷设施,例如,发送文件
- Koa 更加模块化
Koa 对中间件的依赖较少
- 例如,不使用"body parsing"中间件,而是使用 body 解析函数
Koa 抽象 node 的 request 和 response
- 减少攻击
- 更少的用户体验
- 恰当的流处理
Koa 路由(第三方库支持)
- 由于 Express 带有自己的路由,而 Koa 没有任何内置路由,但是有 Koa-router 和 Koa-route 第三方库可用,同样的,就像我们在 Express 中有 helmet 保证安全,对于 Koa 我们有 Koa-helmet 和一些列的第三方库可用
# JS 作用域,作用域链,执行上下文,执行上下文栈,AO,VO
作用域:作用域是程序源代码定义变量的区域,它规定了如何查找变量,也就是当前执行代码对变量的访问权限,JS 采用的是词法作用域,也就是静态作用域,因此,函数的作用域是在函数定义的时候就确定的,函数有一个内部属性 [[scope]],当函数创建的时候,就会保存所有父变量对象到其中,你可以理解 [[scope]] 就是所有父变量对象的层级链,但是注意:[[scope]] 并不代表完整的作用域链!
作用域链:由多个执行上下文的变量对象 VO 构成的链表执行上下文:包括 VO(Variable Object)变量对象,作用域链,this
执行上下文栈:当执行一个函数的时候,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出
VO(Variable Object):变量对象,随着执行上下文的创建而产生,用来存储上下文的函数声明,函数形参和变量
AO(Active Object):活动对象,在 global 全局上下文中,变量对象也是全局对象自身,在函数执行上下文中,变量对象被表示为活动对象 AO。
举个例子:
var scope = 'global scope'
function checkscope() {
var scope2 = 'local scope'
return scope2
}
checkscope()
2
3
4
5
6
执行过程如下:函数创建的时候,保存作用域链到函数的[[scope]]属性
checkscope.[[scope]] = [globalContext.VO]
函数执行的时候,创建执行上下文,压入执行上下文栈中
ECStack = [checkscopeContext, globalContext]
函数并不会立即执行,需要做一些准备工作,第一步,复制函数的[[scope]]属性创建作用域链
checkscopeContext = {
Scope: checkscope.[[socpe]]
}
2
3
第二步,使用 arguments 创建活动对象 AO,随后初始化,加入形参,函数声明,变量声明
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: undefined
},
Scope: checkscope.[[scope]]
}
2
3
4
5
6
7
8
9
第三部,将 AO 插入作用域链顶部
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: undefined
},
Scope: [AO, [[scope]]]
}
2
3
4
5
6
7
8
9
准备工作完毕,开始执行函数,更新 AO 的属性值
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: 'local scope'
},
Scope: [AO, [[scope]]]
}
2
3
4
5
6
7
8
9
查询到 scope2 的值之后,函数返回执行完毕,将函数执行上下文出栈
ECStack = [globalContext]
# 说一下 this
ECMA 规范中规定:this 的类型是规范类型中 Reference 类型
Reference 类型有三部分组成:
- base value
- referenced name
- strict reference
其中的 base value 跟 this 的值有关,如果 Reference 类型是对象就可以通过 GetBase(ref)去获取 base value 赋值给 this,也就是说 this 其实是跟 ref 有关,执行代码过程中,会计算 Member Expression 的结果赋值给 ref,那什么是 MemberExpression 呢
MemberExpression 有以下五种
- PrimaryExpression // 原始表达式 可以参见《JavaScript 权威指南第四章》
- FunctionExpression // 函数定义表达式
- MemberExpression [ Expression ] // 属性访问表达式
- MemberExpression . IdentifierName // 属性访问表达式
- new MemberExpression Arguments // 对象创建表达式
这个时候关键就是看 ECMA 规范中如何处理 MemberExpression,看它的结果是否是 reference 类型,如果不是,this 就指向 undefined,如果是,就进一步判断 reference 类型是否是对象,是的话通过 GetBase(ref)去获取 base value 赋值给 this,否则 this 指向全局环境 window(或者严格模式为 undefined)
# 闭包
ECMAScript 中,闭包指的是:
- 从理论角度:所有的函数。因为它们都在创建的时候就将上层上下文的数据保存起来了。哪怕是简单的全局变量也是如此,因为函数中访问全局变量就相当于是在访问自由变量,这个时候使用最外层的作用域。
- 从实践角度:以下函数才算是闭包:
- 即使创建它的上下文已经销毁,它仍然存在(比如,内部函数从父函数中返回)
- 在代码中引用了自由变量
闭包中的变量并不保存中栈内存中,而是保存在堆内存中。
# 小程序与 H5 的区别
运行环境不同
- 小程序是一种应用,运行的环境是微信(App),开发过程也只用到一部分 H5 技术,小程序的运行环境是微信开发团队基于浏览器内核完全重构的一个内置解析器,针对性做了优化,配合自己定义的开发语言标准,提升了小程序的性能。
- H5 是一种技术,运行在浏览器环境
开发成本不同
- 小程序提供的 API 不用考虑浏览器的兼容性,开发成本低
- H5 可定制化程度非常高(涉及开发工具(vscode、Atom 等)、前端框架(Angular、react 等)、模块管理工具(Webpack 、Browserify 等)、任务管理工具(Grunt、Gulp 等),还有UI 库选择、接口调用工具(ajax、Fetch Api 等)、浏览器兼容性等等),需要关注项目中各种外部库的版本迭代和版本升级,因此开发成本较高
获取系统级权限的不同
- 微信小程序相对于 H5 能获得更多的系统权限,比如网络通信状态、数据缓存能力等,这些系统级权限都可以和微信小程序无缝衔接
运行流畅度的不同
- 微信小程序,它的代码直接在微信上运行,省去了通过浏览器渲染的步骤
- 打开 H5,实际上是打开一个网页,而网页需要在浏览器中渲染
# 小程序与普通网页开发的区别
普通网页开发
网页开发渲染线程和脚本线程是互斥的,开发者可以使用到各种浏览器暴露出来的 DOM API,进行 DOM 选中和操作;而且网页开发者需要面对的环境是各式各样的浏览器,PC 端需要面对 IE、Chrome、360、Firefox 等浏览器,在移动端需要面对 Safari、Chrome 以及 iOS、Android 系统中的各式 WebView 。
小程序
渲染层和逻辑层是分开运行在不同的线程当中,逻辑层运行在 JSCore 中,并没有一个完整浏览器对象,因而缺少相关的 DOM API 和 BOM API。这一区别导致了前端开发非常熟悉的一些库,例如 jQuery、 Zepto 等,在小程序中是无法运行的。同时 JSCore 的环境同 NodeJS 环境也是不尽相同,所以一些 NPM 的包在小程序中也是无法运行的。小程序开发过程中需要面对的是两大操作系统 iOS 和 Android 的微信客户端,以及用于辅助开发的小程序开发者工具。
# 小程序原理
小程序的框架包含两部分,分别是渲染层和AppService 逻辑层,渲染层的界面使用了WebView 进行渲染;逻辑层采用JsCore线程运行 JS 脚本,进行逻辑处理、数据请求及接口调用等,一个小程序存在多个界面,所以渲染层存在多个 WebView 线程,这两个线程的通信会经由微信客户端进行中转,逻辑层把数据变化通知到渲染层,触发渲染层页面更新,渲染层把触发的事件通知到逻辑层进行业务处理。

解析(从下往上看):
1、最底层是微信,当我们发版时小程序开发工具会把我们的代码和框架一起进行打包,当我们在微信里打开小程序时其实微信会把打包好的代码下载到微信 app 里,这样我们就可以像在开发工具里一样在微信里运行我们的小程序了。
2、native 层就是小程序的框架,这个框架里封装了 ui 层组件和逻辑层组件,这些组件可以通过微信 app 提供的接口调用手机硬件信息。
3、最上层的两个框,是我们真正需要进行操作的视图层和逻辑层,视图层和逻辑层的交互是通过数据经由 native 层进行交互的。视图层和逻辑层都可以调用 native 框架里封装好的组件和方法。
# 小程序的生命周期
关于小程序的生命周期,可以分为两个部分来理解:应用生命周期和页面生命周期。
应用的生命周期:
1、用户首次打开小程序,触发 onLaunch(全局只触发一次)。
2、小程序初始化完成后,触发 onShow 方法,监听小程序显示。
3、小程序从前台进入后台,触发 onHide 方法。
4、小程序从后台进入前台显示,触发 onShow 方法。
5、小程序后台运行一定时间,或系统资源占用过高,会被销毁。
页面生命周期:
1、小程序注册完成后,加载页面,触发 onLoad 方法。
2、页面载入后触发 onShow 方法,显示页面。
3、首次显示页面,会触发 onReady 方法,渲染页面元素和样式,一个页面只会调用一次。
4、当小程序后台运行或跳转到其他页面时,触发 onHide 方法。
5、当小程序有后台进入到前台运行或重新进入页面时,触发 onShow 方法。
6、当使用重定向方法 wx.redirectTo()或关闭当前页返回上一页 wx.navigateBack(),触发 onUnload。
同时,应用生命周期会影响到页面生命周期。
# 小程序打包怎么实现的呢?
这就涉及到这个编辑器的实现原理和方式了,它本身也是基于 WEB 技术体系实现的,nwjs+react,nwjs 是什么:简单是说就是 node+webkit,node 提供给我们本地 api 能力,而 webkit 提供给我们 web 能力,两者结合就能让我们使用 JS+HTML 实现本地应用程序。既然有 nodejs,那上面的打包选项里的功能就好实现了。
- ES6 转 ES5:引入 babel-core 的 node 包
- CSS 补全:引入 postcss 和 autoprefixer 的 node 包
- 代码压缩:引入 uglifyjs 的 node 包
注:在 Android 上使用的 x5 内核,对 ES6 的支持不好,要兼容的话,要么使用 ES5 的语法或者引入 babel-polyfill 兼容库。
打包后的目录结构如下:
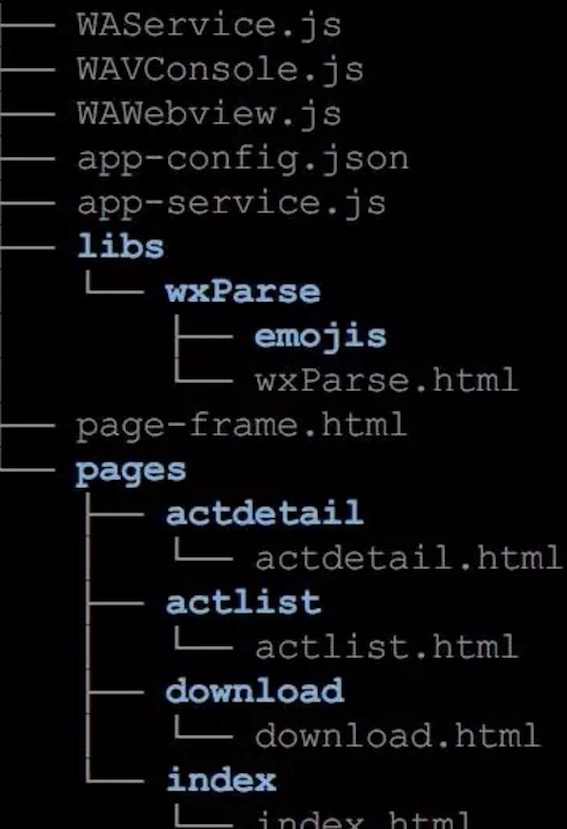
1、WAService.js 框架 JS 库,提供逻辑层基础的 API 能力 2、WAWebview.js 框架 JS 库,提供视图层基础的 API 能力 3、WAConsole.js 框架 JS 库,控制台 4、app-config.js 小程序完整的配置,包含我们通过 app.json 里的所有配置,综合了默认配置型 5、app-service.js 我们自己的 JS 代码,全部打包到这个文件 6、page-frame.html 小程序视图的模板文件,所有的页面都使用此加载渲染,且所有的 WXML 都拆解为 JS 实现打包到这里 7、pages 所有的页面,这个不是我们之前的 wxml 文件了,主要是处理 WXSS 转换,使用 js 插入到 header 区域。
# replace 方法
replace(regexp/substr,replacement) 方法执行的是查找并替换的操作。
它会查找与 regexp 相匹配的子字符串,然后用 replacement 来替换这些子串。如果 regexp 具有全局标志 g,那么 replace() 方法将替换所有匹配的子串。否则,它只替换第一个匹配子串。
replacement 可以是字符串,也可以是函数。如果它是字符串,那么每个匹配都将由字符串替换。但是 replacement 中的 $ 字符具有特定的含义。如下表所示,它说明从模式匹配得到的字符串将用于替换。
| 字符 | 替换文本 |
|---|---|
| $1、$2、...、$99 | 与 regexp 中的第 1 到第 99 个子表达式相匹配的文本。 |
| $& | 与 regexp 相匹配的子串。 |
| $` | 位于匹配子串左侧的文本。 |
| $' | 位于匹配子串右侧的文本。 |
| $$ | 直接量符号。 |
注意:ECMAScript v3 规定,replace() 方法的参数 replacement 可以是函数而不是字符串。在这种情况下,每个匹配都调用该函数,它返回的字符串将作为替换文本使用。该函数的第一个参数是匹配模式的字符串。接下来的参数是与模式中的子表达式匹配的字符串,可以有 0 个或多个这样的参数。接下来的参数是一个整数,声明了匹配在 stringObject 中出现的位置。最后一个参数是 stringObject 本身。
# 数据类型
# 基本数据类型
基本数据类型共有 6 种:
- Sting
- Number
- Boolean
- null
- undefined
- Symbol
基本数据类型保存在栈内存中,因为基本数据类型占用空间小、大小固定,通过按值来访问,属于被频繁使用的数据。
# 引用数据类型
Array,Function,Object...可以认为除了上文提到的基本数据类型以外,所有类型都是引用数据类型。
引用数据类型存储在堆内存中,因为引用数据类型占据空间大、大小不固定。 如果存储在栈中,将会影响程序运行的性能; 引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。 当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体
# 栈内存和堆内存
# 优缺点
在 JS 中,基本数据类型变量大小固定,并且操作简单容易,所以把它们放入栈中存储。
引用类型变量大小不固定,所以把它们分配给堆中,让他们申请空间的时候自己确定大小,这样把它们分开存储能够使得程序运行起来占用的内存最小。
栈内存由于它的特点,所以它的系统效率较高。 堆内存需要分配空间和地址,还要把地址存到栈中,所以效率低于栈。
# 垃圾回收
栈内存中变量一般在它的当前执行环境结束就会被销毁被垃圾回收制回收, 而堆内存中的变量则不会,因为不确定其他的地方是不是还有一些对它的引用。 堆内存中的变量只有在所有对它的引用都结束的时候才会被回收
# function.length
length 是函数对象的一个属性值,指该函数有多少个必须要传入的参数,即形参的个数。
形参的数量不包括剩余参数个数,仅包括第一个具有默认值之前的参数个数
# requestAnimationFrame
window.requestAnimationFrame() 告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行
回调函数会被传入
DOMHighResTimeStamp(opens new window)参数,该参数与performance.now()(opens new window)的返回值相同,它表示requestAnimationFrame()开始去执行回调函数的时刻返回值:一个
long整数,请求 ID ,是回调列表中唯一的标识。是个非零值,没别的意义。你可以传这个值给window.cancelAnimationFrame()(opens new window) 以取消回调函数
为了提高性能和电池寿命,因此在大多数浏览器里,当requestAnimationFrame() 运行在后台标签页或者隐藏的iframe (opens new window) 里时,requestAnimationFrame() 会被暂停调用以提升性能和电池寿命。
# 如何对小数取整
- parseInt(string, radix):当参数 radix 的值为 0,或没有设置该参数时,parseInt() 会根据 string 来判断数字的基数。举例:如果 string 以 "0x" 开头,parseInt() 会把 string 的其余部分解析为十六进制的整数。如果 string 以 0 开头,那么 ECMAScript v3 允许 parseInt() 的一个实现把其后的字符解析为八进制或十六进制的数字。如果 string 以 1 ~ 9 的数字开头,parseInt() 将把它解析为十进制的整数
- Math.trunc() 方法会将数字的小数部分去掉,只保留整数部分。(ceil,floor,round 等方法也可以)
- 二进制位运算:JS 进行位运算之前,会将操作数转成整数(非法整数转为 0),并且进行取整操作(位运算只针对整数部分)
- ~~n 双重位取反(Double bitwise NOT)
- n | n 位或运算(Bitwise OR)
- n | 0 和 0 的位或运算(Bitwise OR with 0)
- n << 0 位左移运算 0 位(Bitwise left shift)
- n >> 0 位右移运算 0 位(Bitwise right shift)
- n & n 为与运算(Bitwise AND)
Math.trunc ||
(Math.trunc = function(v) {
return v < 0 ? Math.ceil(v) : Math.floor(v) // 使用Math.floor和Math.ceil方法
})
Math.trunc(13.37) // 13
Math.trunc(42.84) // 42
Math.trunc(0.123) // 0
Math.trunc(-0.123) // -0
Math.trunc('-1.123') // -1
Math.trunc(NaN) // NaN
Math.trunc('foo') // NaN
Math.trunc() // NaN
;(~~1.23 - // 1
1.2) |
(-1.2 - // - 1
1.2) |
0 // - 1
3.4 >> 0 // 3
3.2 << 0 // 3
5.5 & 5.5 // 5
~~'1.2' // 1.2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 位运算优缺点
用位操作进行整数转换的优点,大概包括如下:
性能更快
代码字符可以更少(比如 n | 0 或者~~n)
用位操作进行整数转换的缺点,大概包括如下:
- 代码不易懂
- 可能不能通过 jsLint
- 只支持 32 位以内的数据,超过范围就会得出错误的结果。
对于“只支持 32 位以内的数据,超过范围就会得出错误的结果”这一点,因为位运算会把运算元当做 32 位带符号的整数,其范围是-2,147,483,648 到 2147483647 (0x7FFFFFFFF),超过范围就不奏效了。
// Safe
;((((((((2147483647.5918 & 0xffffffff) ===
2147483647(2147483647 & 0xffffffff)) ===
2147483647(200.59082098 & 0xffffffff)) ===
200(0x7fffffff & 0xffffffff)) ===
0x7fffffff(
// Unsafe
2147483648 & 0xffffffff
)) ===
-2147483648(-2147483649 & 0xffffffff)) ===
2147483647(0x80000000 & 0xffffffff)) ===
-2147483648(3000000000.5 & 0xffffffff)) ===
-1294967296
2
3
4
5
6
7
8
9
10
11
12
13
为了能够提高性能,又保证超过范围的时候安全可靠,可以考虑下面的 polyfill
function trunc(n) {
if (n > -0x80000000 && n < 0x80000000) {
return n & 0xffffffff //此处可以用 ~~n,n | 0等等
}
return Math.trunc(n)
}
2
3
4
5
6
# 为什么通常在发送数据埋点请求的时候使用的是 1x1 像素的透明 gif 图片?
- 无跨域问题(img 天然支持跨域)
- 不阻塞页面加载,只要 new Image 对象就好了,一般情况下也不需要 append 到 DOM 中,通过它的 onerror 和 onload 事件来检测发送状态。
- gif 的最低合法体积最小(最小的 bmp 文件需要 74 个字节,png 需要 67 个字节,而合法的 gif,只需要 43 个字节)
- 图片请求不占用 Ajax 请求限额
示例代码
<script type="text/javascript">
var thisPage = location.href
var referringPage = document.referrer ? document.referrer : 'none'
var beacon = new Image()
beacon.src =
'http://www.example.com/logger/beacon.gif?page=' +
encodeURI(thisPage) +
'&ref=' +
encodeURI(referringPage)
</script>
2
3
4
5
6
7
8
9
10
# input 搜索如何防抖,如何处理中文输入
参考 vue 源码对 v-model 的实现中,对输入中文的处理
<input id="myinput" />
function debounce(timeout) {
var timer
function input(e) {
if (e.target.composing) {
return
}
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
console.log(e.target.value)
timer = null
}, timeout)
}
return input
}
function onCompositionStart(e) {
e.target.composing = true
}
function onCompositionEnd(e) {
//console.log(e.target)
e.target.composing = false
var event = document.createEvent('HTMLEvents')
event.initEvent('input')
e.target.dispatchEvent(event)
}
var input_dom = document.getElementById('myinput')
input_dom.addEventListener('input', debounce(1000))
input_dom.addEventListener('compositionstart', onCompositionStart)
input_dom.addEventListener('compositionend', onCompositionEnd)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
- 输入到 input 框触发 input 事件
- 失去焦点后内容有改变触发 change 事件
- 识别到你开始使用中文输入法触发**compositionstart **事件
- 未输入结束但还在输入中触发**compositionupdate **事件
- 输入完成(也就是我们回车或者选择了对应的文字插入到输入框的时刻)触发 compositionend 事件
# JavaScript 有几种类型的值?你能画一下他们的内存图吗?
- 栈:原始数据类型(Undefined、Null、Boolean、Number、String)
- 堆:引用数据类型(对象、数组和函数)
两种类型的区别是:存储位置不同。
原始数据类型直接存储在栈(stack)中的简单数据段,占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储。
引用数据类型存储在堆(heap)中的对象,占据空间大、大小不固定。如果存储在栈中,将会影响程序运行的性能;引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
# 什么是堆?什么是栈?它们之间有什么区别和联系?
堆和栈的概念存在于数据结构中和操作系统内存中。
在数据结构中,栈中数据的存取方式为先进后出。而堆是一个优先队列,是按优先级来进行排序的,优先级可以按照大小来规定。完全二叉树是堆的一种实现方式。
在操作系统中,内存被分为栈区和堆区。
栈区内存由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆区内存一般由程序员分配释放,若程序员不释放,程序结束时可能由垃圾回收机制回收。
# 内部属性 [[Class]] 是什么?
所有 typeof 返回值为 "object" 的对象(如数组)都包含一个内部属性 [[Class]](我们可以把它看作一个内部的分类,而非传统的面向对象意义上的类)。这个属性无法直接访问,一般通过 Object.prototype.toString(..) 来查看。例如:
Object.prototype.toString.call([1, 2, 3])
// "[object Array]"
Object.prototype.toString.call(/regex-literal/i)
// "[object RegExp]"
// 我们自己创建的类就不会有这份特殊待遇,因为 toString() 找不到 toStringTag 属性时只好返回默认的 Object 标签
// 默认情况类的[[Class]]返回[object Object]
class Class1 {}
Object.prototype.toString.call(new Class1()) // "[object Object]"
// 需要定制[[Class]]
class Class2 {
get [Symbol.toStringTag]() {
return 'Class2'
}
}
Object.prototype.toString.call(new Class2()) // "[object Class2]"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# undefined 与 undeclared 的区别?
已在作用域中声明但还没有赋值的变量,是 undefined 的。相反,还没有在作用域中声明过的变量,是 undeclared 的。
对于 undeclared 变量的引用,浏览器会报引用错误,如 ReferenceError: b is not defined 。但是我们可以使用 typeof 的安全防范机制来避免报错,因为对于 undeclared(或者 not defined )变量,typeof 会返回 "undefined"。
# null 和 undefined 的区别?
首先 Undefined 和 Null 都是基本数据类型,这两个基本数据类型分别都只有一个值,就是 undefined 和 null。
undefined 代表的含义是未定义,null 代表的含义是空对象。一般变量声明了但还没有定义的时候会返回 undefined,null 主要用于赋值给一些可能会返回对象的变量,作为初始化。
undefined 在 js 中不是一个保留字,这意味着我们可以使用 undefined 来作为一个变量名,这样的做法是非常危险的,它会影响我们对 undefined 值的判断。但是我们可以通过一些方法获得安全的 undefined 值,比如说 void 0。
当我们对两种类型使用 typeof 进行判断的时候,Null 类型化会返回 “object”,这是一个历史遗留的问题。当我们使用双等号对两种类型的值进行比较时会返回 true,使用三个等号时会返回 false。
# 如何获取安全的 undefined 值?
因为 undefined 是一个标识符,所以可以被当作变量来使用和赋值,但是这样会影响 undefined 的正常判断。
表达式 void ___ 没有返回值,因此返回结果是 undefined。void 并不改变表达式的结果,只是让表达式不返回值。
按惯例我们用 void 0 来获得 undefined。
# JavaScript 原型,原型链? 有什么特点?
在 js 中我们是使用构造函数来新建一个对象的,每一个构造函数的内部都有一个 prototype 属性值,这个属性值是一个对象,这个对象包含了可以由该构造函数的所有实例共享的属性和方法。当我们使用构造函数新建一个对象后,在这个对象的内部将包含一个指针,这个指针指向构造函数的 prototype 属性对应的值,在 ES5 中这个指针被称为对象的原型。一般来说我们是不应该能够获取到这个值的,但是现在浏览器中都实现了 proto 属性来让我们访问这个属性,但是我们最好不要使用这个属性,因为它不是规范中规定的。ES5 中新增了一个 Object.getPrototypeOf() 方法,我们可以通过这个方法来获取对象的原型。
当我们访问一个对象的属性时,如果这个对象内部不存在这个属性,那么它就会去它的原型对象里找这个属性,这个原型对象又会有自己的原型,于是就这样一直找下去,也就是原型链的概念。原型链的尽头一般来说都是 Object.prototype 所以这就是我们新建的对象为什么能够使用 toString() 等方法的原因。
特点:
JavaScript 对象是通过引用来传递的,我们创建的每个新对象实体中并没有一份属于自己的原型副本。当我们修改原型时,与之相关的对象也会继承这一改变。
# 在 js 中不同进制数字的表示方式
- 以 0X、0x 开头的表示为十六进制。
- 以 0、0O、0o 开头的表示为八进制。
- 以 0B、0b 开头的表示为二进制格式。
# js 中整数的安全范围是多少?
安全整数指的是,在这个范围内的整数转化为二进制存储的时候不会出现精度丢失,能够被“安全”呈现的最大整数是 2^53 - 1,即 9007199254740991,在 ES6 中被定义为 Number.MAX_SAFE_INTEGER。最小整数是-9007199254740991,在 ES6 中被定义为 Number.MIN_SAFE_INTEGER。
如果某次计算的结果得到了一个超过 JavaScript 数值范围的值,那么这个值会被自动转换为特殊的 Infinity 值。如果某次计算返回了正或负的 Infinity 值,那么该值将无法参与下一次的计算。判断一个数是不是有穷的,可以使用 isFinite 函数来判断。
# typeof NaN 的结果是什么?
NaN 意指“不是一个数字”(not a number),NaN 是一个“警戒值”(sentinel value,有特殊用途的常规值),用于指出数字类型中的错误情况,即“执行数学运算没有成功,这是失败后返回的结果”。
typeof NaN // "number"
NaN 是一个特殊值,它和自身不相等,是唯一一个非自反(自反,reflexive,即 x === x 不成立)的值。而 NaN != NaN 为 true。
# isNaN 和 Number.isNaN 函数的区别?
函数 isNaN 接收参数后,会尝试将这个参数转换为数值,任何不能被转换为数值的的值都会返回 true,因此非数字值传入也会返回 true ,会影响 NaN 的判断。
函数 Number.isNaN 会首先判断传入参数是否为数字,如果是数字再继续判断是否为 NaN ,这种方法对于 NaN 的判断更为准确。
# Array 构造函数只有一个参数值时的表现?
Array 构造函数只带一个数字参数的时候,该参数会被作为数组的预设长度(length),而非只充当数组中的一个元素。这样创建出来的只是一个空数组,只不过它的 length 属性被设置成了指定的值。
构造函数 Array(..) 不要求必须带 new 关键字。不带时,它会被自动补上。
# 其他值到字符串的转换规则?
规范的 9.8 节中定义了抽象操作 ToString ,它负责处理非字符串到字符串的强制类型转换。
(1)Null 和 Undefined 类型 ,null 转换为 "null",undefined 转换为 "undefined",
(2)Boolean 类型,true 转换为 "true",false 转换为 "false"。
(3)Number 类型的值直接转换,不过那些极小和极大的数字会使用指数形式。
(4)Symbol 类型的值直接转换,但是只允许显式强制类型转换,使用隐式强制类型转换会产生错误。
(5)对普通对象来说,除非自行定义 toString() 方法,否则会调用 toString()(Object.prototype.toString())来返回内部属性 [[Class]] 的值,如"[object Object]"。如果对象有自己的 toString() 方法,字符串化时就会调用该方法并使用其返回值。
# 其他值到数字值的转换规则?
有时我们需要将非数字值当作数字来使用,比如数学运算。为此 ES5 规范在 9.3 节定义了抽象操作 ToNumber。
(1)Undefined 类型的值转换为 NaN。
(2)Null 类型的值转换为 0。
(3)Boolean 类型的值,true 转换为 1,false 转换为 0。
(4)String 类型的值转换如同使用 Number() 函数进行转换,如果包含非数字值则转换为 NaN,空字符串为 0。
(5)Symbol 类型的值不能转换为数字,会报错。
(6)对象(包括数组)会首先被转换为相应的基本类型值,如果返回的是非数字的基本类型值,则再遵循以上规则将其强制转换为数字。
为了将值转换为相应的基本类型值,抽象操作 ToPrimitive 会首先(通过内部操作 DefaultValue)检查该值是否有 valueOf() 方法。如果有并且返回基本类型值,就使用该值进行强制类型转换。如果没有就使用 toString() 的返回值(如果存在)来进行强制类型转换。
如果 valueOf() 和 toString() 均不返回基本类型值,会产生 TypeError 错误。
# 其他值到布尔类型的值的转换规则?
ES5 规范 9.2 节中定义了抽象操作 ToBoolean,列举了布尔强制类型转换所有可能出现的结果。
以下这些是假值:
- undefined
- null
- false
- +0、-0 和 NaN
- ""
假值的布尔强制类型转换结果为 false。从逻辑上说,假值列表以外的都应该是真值。
# {} 和 [] 的 valueOf 和 toString 的结果是什么?
{} 的 valueOf 结果为 {} ,toString 的结果为 "[object Object]"
[] 的 valueOf 结果为 [] ,toString 的结果为 ""
# 什么是假值对象?
浏览器在某些特定情况下,在常规 JavaScript 语法基础上自己创建了一些外来值,这些就是“假值对象”。假值对象看起来和普通对象并无二致(都有属性,等等),但将它们强制类型转换为布尔值时结果为 false 最常见的例子是 document.all,它是一个类数组对象,包含了页面上的所有元素,由 DOM(而不是 JavaScript 引擎)提供给 JavaScript 程序使用。
# ~ 操作符的作用?
~ 返回 2 的补码,并且 ~ 会将数字转换为 32 位整数,因此我们可以使用 ~ 来进行取整操作。
~x 大致等同于 -(x+1)。
# 解析字符串中的数字和将字符串强制类型转换为数字的返回结果都是数字,它们之间的区别是什么?
解析允许字符串(如 parseInt() )中含有非数字字符,解析按从左到右的顺序,如果遇到非数字字符就停止。而转换(如 Number ())不允许出现非数字字符,否则会失败并返回 NaN。
# + 操作符什么时候用于字符串的拼接?
根据 ES5 规范 11.6.1 节,如果某个操作数是字符串或者能够通过以下步骤转换为字符串的话,+ 将进行拼接操作。如果其中一个操作数是对象(包括数组),则首先对其调用 ToPrimitive 抽象操作,该抽象操作再调用 [[DefaultValue]],以数字作为上下文。如果不能转换为字符串,则会将其转换为数字类型来进行计算。
简单来说就是,如果 + 的其中一个操作数是字符串(或者通过以上步骤最终得到字符串),则执行字符串拼接,否则执行数字加法。
那么对于除了加法的运算符来说,只要其中一方是数字,那么另一方就会被转为数字。
# 什么情况下会发生布尔值的隐式强制类型转换?
(1) if (..) 语句中的条件判断表达式。
(2) for ( .. ; .. ; .. ) 语句中的条件判断表达式(第二个)。
(3) while (..) 和 do..while(..) 循环中的条件判断表达式。
(4) ? : 中的条件判断表达式。
(5) 逻辑运算符 ||(逻辑或)和 &&(逻辑与)左边的操作数(作为条件判断表达式)。
# || 和 && 操作符的返回值?
|| 和 && 首先会对第一个操作数执行条件判断,如果其不是布尔值就先进行 ToBoolean 强制类型转换,然后再执行条件判断。
对于 || 来说,如果条件判断结果为 true 就返回第一个操作数的值,如果为 false 就返回第二个操作数的值。
&& 则相反,如果条件判断结果为 true 就返回第二个操作数的值,如果为 false 就返回第一个操作数的值。
|| 和 && 返回它们其中一个操作数的值,而非条件判断的结果
# Symbol 值的强制类型转换?
ES6 允许从 Symbol 到字符串的显式强制类型转换,然而隐式强制类型转换会产生错误
Symbol 值不能够被强制类型转换为数字(显式和隐式都会产生错误)
Symbol 值可以被强制类型转换为布尔值(显式和隐式结果都是 true )
# 如何将字符串转化为数字,例如 '12.3b'?
(1)使用 Number() 方法,前提是所包含的字符串不包含不合法字符。
(2)使用 parseInt() 方法,parseInt() 函数可解析一个字符串,并返回一个整数。还可以设置要解析的数字的基数。当基数的值为 0,或没有设置该参数时,parseInt() 会根据 string 来判断数字的基数。
(3)使用 parseFloat() 方法,该函数解析一个字符串参数并返回一个浮点数。
(4)使用 + 操作符的隐式转换,前提是所包含的字符串不包含不合法字符。
# 如何将浮点数点左边的数每三位添加一个逗号,如 12000000.11 转化为『12,000,000.11』?
// 方法一
function format(number) {
return number && number.replace(/(?!^)(?=(\d{3})+\.)/g, ',')
}
// 方法二
function format1(number) {
return Intl.NumberFormat().format(number)
}
// 方法三
function format2(number) {
return number.toLocaleString('en')
}
2
3
4
5
6
7
8
9
10
11
12
# 如何实现数组的随机排序?
// (1)使用数组 sort 方法对数组元素随机排序,让 Math.random() 出来的数与 0.5 比较,如果大于就返回 1 交换位置,如果小于就返回 -1,不交换位置。
function randomSort(a, b) {
return Math.random() > 0.5 ? -1 : 1
}
// 缺点:每个元素被派到新数组的位置不是随机的,原因是 sort() 方法是依次比较的。
// (2)随机从原数组抽取一个元素,加入到新数组
function randomSort(arr) {
var result = []
while (arr.length > 0) {
var randomIndex = Math.floor(Math.random() * arr.length)
result.push(arr[randomIndex])
arr.splice(randomIndex, 1)
}
return result
}
// (3)随机交换数组内的元素(洗牌算法类似)
function randomSort(arr) {
var index,
randomIndex,
temp,
len = arr.length
for (index = 0; index < len; index++) {
randomIndex = Math.floor(Math.random() * (len - index)) + index
temp = arr[index]
arr[index] = arr[randomIndex]
arr[randomIndex] = temp
}
return arr
}
// es6
function randomSort(array) {
let length = array.length
if (!Array.isArray(array) || length <= 1) return
for (let index = 0; index < length - 1; index++) {
let randomIndex = Math.floor(Math.random() * (length - index)) + index
;[array[index], array[randomIndex]] = [array[randomIndex], array[index]]
}
return array
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# javascript 创建对象的几种方式?
我们一般使用字面量的形式直接创建对象,但是这种创建方式对于创建大量相似对象的时候,会产生大量的重复代码。但 js 和一般的面向对象的语言不同,在 ES6 之前它没有类的概念。但是我们可以使用函数来进行模拟,从而产生出可复用的对象创建方式,我了解到的方式有这么几种:
(1)第一种是工厂模式,工厂模式的主要工作原理是用函数来封装创建对象的细节,从而通过调用函数来达到复用的目的。但是它有一个很大的问题就是创建出来的对象无法和某个类型联系起来,它只是简单的封装了复用代码,而没有建立起对象和类型间的关系。
(2)第二种是构造函数模式。js 中每一个函数都可以作为构造函数,只要一个函数是通过 new 来调用的,那么我们就可以把它称为构造函数。执行构造函数首先会创建一个对象,然后将对象的原型指向构造函数的 prototype 属性,然后将执行上下文中的 this 指向这个对象,最后再执行整个函数,如果返回值不是对象,则返回新建的对象。因为 this 的值指向了新建的对象,因此我们可以使用 this 给对象赋值。构造函数模式相对于工厂模式的优点是,所创建的对象和构造函数建立起了联系,因此我们可以通过原型来识别对象的类型。但是构造函数存在一个缺点就是,造成了不必要的函数对象的创建,因为在 js 中函数也是一个对象,因此如果对象属性中如果包含函数的话,那么每次我们都会新建一个函数对象,浪费了不必要的内存空间,因为函数是所有的实例都可以通用的。
(3)第三种模式是原型模式,因为每一个函数都有一个 prototype 属性,这个属性是一个对象,它包含了通过构造函数创建的所有实例都能共享的属性和方法。因此我们可以使用原型对象来添加公用属性和方法,从而实现代码的复用。这种方式相对于构造函数模式来说,解决了函数对象的复用问题。但是这种模式也存在一些问题,一个是没有办法通过传入参数来初始化值,另一个是如果存在一个引用类型如 Array 这样的值,那么所有的实例将共享一个对象,一个实例对引用类型值的改变会影响所有的实例。
(4)第四种模式是组合使用构造函数模式和原型模式,这是创建自定义类型的最常见方式。因为构造函数模式和原型模式分开使用都存在一些问题,因此我们可以组合使用这两种模式,通过构造函数来初始化对象的属性,通过原型对象来实现函数方法的复用。这种方法很好的解决了两种模式单独使用时的缺点,但是有一点不足的就是,因为使用了两种不同的模式,所以对于代码的封装性不够好。
(5)第五种模式是动态原型模式,这一种模式将原型方法赋值的创建过程移动到了构造函数的内部,通过对属性是否存在的判断,可以实现仅在第一次调用函数时对原型对象赋值一次的效果。这一种方式很好地对上面的混合模式进行了封装。
(6)第六种模式是寄生构造函数模式,这一种模式和工厂模式的实现基本相同,我对这个模式的理解是,它主要是基于一个已有的类型,在实例化时对实例化的对象进行扩展。这样既不用修改原来的构造函数,也达到了扩展对象的目的。它的一个缺点和工厂模式一样,无法实现对象的识别。
# JavaScript 继承的几种实现方式?
我了解的 js 中实现继承的几种方式有:
(1)第一种是以原型链的方式来实现继承,但是这种实现方式存在的缺点是,在包含有引用类型的数据时,会被所有的实例对象所共享,容易造成修改的混乱。还有就是在创建子类型的时候不能向超类型传递参数。
(2)第二种方式是使用借用构造函数的方式,这种方式是通过在子类型的函数中调用超类型的构造函数来实现的,这一种方法解决了不能向超类型传递参数的缺点,但是它存在的一个问题就是无法实现函数方法的复用,并且超类型原型定义的方法子类型也没有办法访问到。
(3)第三种方式是组合继承,组合继承是将原型链和借用构造函数组合起来使用的一种方式。通过借用构造函数的方式来实现类型的属性的继承,通过将子类型的原型设置为超类型的实例来实现方法的继承。这种方式解决了上面的两种模式单独使用时的问题,但是由于我们是以超类型的实例来作为子类型的原型,所以调用了两次超类的构造函数,造成了子类型的原型中多了很多不必要的属性。
(4)第四种方式是原型式继承,原型式继承的主要思路就是基于已有的对象来创建新的对象,实现的原理是,向函数中传入一个对象,然后返回一个以这个对象为原型的对象。这种继承的思路主要不是为了实现创造一种新的类型,只是对某个对象实现一种简单继承,ES5 中定义的 Object.create() 方法就是原型式继承的实现。缺点与原型链方式相同。
(5)第五种方式是寄生式继承,寄生式继承的思路是创建一个用于封装继承过程的函数,通过传入一个对象,然后复制一个对象的副本,然后对象进行扩展,最后返回这个对象。这个扩展的过程就可以理解是一种继承。这种继承的优点就是对一个简单对象实现继承,如果这个对象不是我们的自定义类型时。缺点是没有办法实现函数的复用。
(6)第六种方式是寄生式组合继承,组合继承的缺点就是使用超类型的实例做为子类型的原型,导致添加了不必要的原型属性。寄生式组合继承的方式是使用超类型的原型的副本来作为子类型的原型,这样就避免了创建不必要的属性。
# 寄生式组合继承的实现?
function Person(name) {
this.name = name
}
Person.prototype.sayName = function() {
console.log('My name is ' + this.name + '.')
}
function Student(name, grade) {
Person.call(this, name)
this.grade = grade
}
Student.prototype = Object.create(Person.prototype)
Student.prototype.constructor = Student
Student.prototype.sayMyGrade = function() {
console.log('My grade is ' + this.grade + '.')
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Javascript 的作用域链?
作用域链的作用是保证对执行环境有权访问的所有变量和函数的有序访问,通过作用域链,我们可以访问到外层环境的变量和函数。
作用域链的本质上是一个指向变量对象的指针列表。变量对象是一个包含了执行环境中所有变量和函数的对象。作用域链的前端始终都是当前执行上下文的变量对象。全局执行上下文的变量对象(也就是全局对象)始终是作用域链的最后一个对象。
当我们查找一个变量时,如果当前执行环境中没有找到,我们可以沿着作用域链向后查找。
作用域链的创建过程跟执行上下文的建立有关....
# 谈谈 This 对象的理解
this 是执行上下文中的一个属性,它指向最后一次调用这个方法的对象。在实际开发中,this 的指向可以通过四种调用模式来判断。
- 第一种是函数调用模式,当一个函数不是一个对象的属性时,直接作为函数来调用时,this 指向全局对象。
- 第二种是方法调用模式,如果一个函数作为一个对象的方法来调用时,this 指向这个对象。
- 第三种是构造器调用模式,如果一个函数用 new 调用时,函数执行前会新创建一个对象,this 指向这个新创建的对象。
- 第四种是 apply 、 call 和 bind 调用模式,这三个方法都可以显示的指定调用函数的 this 指向。其中 apply 方法接收两个参数:一个是 this 绑定的对象,一个是参数数组。call 方法接收的参数,第一个是 this 绑定的对象,后面的其余参数是传入函数执行的参数。也就是说,在使用 call() 方法时,传递给函数的参数必须逐个列举出来。bind 方法通过传入一个对象,返回一个 this 绑定了传入对象的新函数。这个函数的 this 指向除了使用 new 时会被改变,其他情况下都不会改变。
这四种方式,使用构造器调用模式的优先级最高,然后是 apply 、 call 和 bind 调用模式,然后是方法调用模式,然后是函数调用模式。
# eval 是做什么的?
它的功能是把对应的字符串解析成 JS 代码并运行。
应该避免使用 eval,不安全,非常耗性能(2 次,一次解析成 js 语句,一次执行)。
# 什么是 DOM 和 BOM?
DOM 指的是文档对象模型,它指的是把文档当做一个对象来对待,这个对象主要定义了处理网页内容的方法和接口。
BOM 指的是浏览器对象模型,它指的是把浏览器当做一个对象来对待,这个对象主要定义了与浏览器进行交互的法和接口。BOM 的核心是 window,而 window 对象具有双重角色,它既是通过 js 访问浏览器窗口的一个接口,又是一个 Global(全局)对象。这意味着在网页中定义的任何对象,变量和函数,都作为全局对象的一个属性或者方法存在。window 对象含有 location 对象、navigator 对象、screen 对象等子对象,并且 DOM 的最根本的对象 document 对象也是 BOM 的 window 对象的子对象。
# 写一个通用的事件侦听器函数。
const EventUtils = {
// 视能力分别使用dom0||dom2||IE方式 来绑定事件
// 添加事件
addEvent: function(element, type, handler) {
if (element.addEventListener) {
element.addEventListener(type, handler, false)
} else if (element.attachEvent) {
element.attachEvent('on' + type, handler)
} else {
element['on' + type] = handler
}
},
// 移除事件
removeEvent: function(element, type, handler) {
if (element.removeEventListener) {
element.removeEventListener(type, handler, false)
} else if (element.detachEvent) {
element.detachEvent('on' + type, handler)
} else {
element['on' + type] = null
}
},
// 获取事件目标
getTarget: function(event) {
return event.target || event.srcElement
},
// 获取 event 对象的引用,取到事件的所有信息,确保随时能使用 event
getEvent: function(event) {
return event || window.event
},
// 阻止事件(主要是事件冒泡,因为 IE 不支持事件捕获)
stopPropagation: function(event) {
if (event.stopPropagation) {
event.stopPropagation()
} else {
event.cancelBubble = true
}
},
// 取消事件的默认行为
preventDefault: function(event) {
if (event.preventDefault) {
event.preventDefault()
} else {
event.returnValue = false
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 事件是什么?IE 与火狐的事件机制有什么区别? 如何阻止冒泡?
- 事件是用户操作网页时发生的交互动作,比如 click/move, 事件除了用户触发的动作外,还可以是文档加载,窗口滚动和大小调整。事件被封装成一个 event 对象,包含了该事件发生时的所有相关信息( event 的属性)以及可以对事件进行的操作( event 的方法)。
- 事件处理机制:IE 支持事件冒泡、Firefox 同时支持两种事件模型,也就是:事件冒泡和事件捕获。
- event.stopPropagation() 或者 ie 下的方法 event.cancelBubble = true;
# 三种事件模型是什么?
事件是用户操作网页时发生的交互动作或者网页本身的一些操作,现代浏览器一共有三种事件模型。
第一种事件模型是最早的 DOM0 级模型,这种模型不会传播,所以没有事件流的概念,但是现在有的浏览器支持以冒泡的方式实现,它可以在网页中直接定义监听函数,也可以通过 js 属性来指定监听函数。这种方式是所有浏览器都兼容的。
第二种事件模型是 IE 事件模型,在该事件模型中,一次事件共有两个过程,事件处理阶段,和事件冒泡阶段。事件处理阶段会首先执行目标元素绑定的监听事件。然后是事件冒泡阶段,冒泡指的是事件从目标元素冒泡到 document,依次检查经过的节点是否绑定了事件监听函数,如果有则执行。这种模型通过 attachEvent 来添加监听函数,可以添加多个监听函数,会按顺序依次执行。
第三种是 DOM2 级事件模型,在该事件模型中,一次事件共有三个过程,第一个过程是事件捕获阶段。捕获指的是事件从 document 一直向下传播到目标元素,依次检查经过的节点是否绑定了事件监听函数,如果有则执行。后面两个阶段和 IE 事件模型的两个阶段相同。这种事件模型,事件绑定的函数是 addEventListener,其中第三个参数可以指定事件是否在捕获阶段执行。
# 事件委托是什么?
事件委托本质上是利用了浏览器事件冒泡的机制。因为事件在冒泡过程中会上传到父节点,并且父节点可以通过事件对象获取到目标节点,因此可以把子节点的监听函数定义在父节点上,由父节点的监听函数统一处理多个子元素的事件,这种方式称为事件代理。
使用事件代理我们可以不必要为每一个子元素都绑定一个监听事件,这样减少了内存上的消耗。并且使用事件代理我们还可以实现事件的动态绑定,比如说新增了一个子节点,我们并不需要单独地为它添加一个监听事件,它所发生的事件会交给父元素中的监听函数来处理。
# 什么是闭包,为什么要用它?
闭包是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,创建的函数可以访问到当前函数的局部变量。
闭包有两个常用的用途。
闭包的第一个用途是使我们在函数外部能够访问到函数内部的变量。通过使用闭包,我们可以通过在外部调用闭包函数,从而在外部访问到函数内部的变量,可以使用这种方法来创建私有变量。
函数的另一个用途是使已经运行结束的函数上下文中的变量对象继续留在内存中,因为闭包函数保留了这个变量对象的引用,所以这个变量对象不会被回收。
其实闭包的本质就是作用域链的一个特殊的应用,只要了解了作用域链的创建过程,就能够理解闭包的实现原理。
# javascript 代码中的 "use strict"; 是什么意思 ? 使用它区别是什么?
use strict 是一种 ECMAscript5 添加的(严格)运行模式,这种模式使得 Javascript 在更严格的条件下运行。
设立"严格模式"的目的,主要有以下几个:
- 消除 Javascript 语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的 Javascript 做好铺垫
区别:
- 禁止使用 with 语句。
- 禁止 this 关键字指向全局对象。
- 对象不能有重名的属性。
回答:
use strict 指的是严格运行模式,在这种模式对 js 的使用添加了一些限制。比如说禁止 this 指向全局对象,还有禁止使用 with 语句等。设立严格模式的目的,主要是为了消除代码使用中的一些不安全的使用方式,也是为了消除 js 语法本身的一些不合理的地方,以此来减少一些运行时的怪异的行为。同时使用严格运行模式也能够提高编译的效率,从而提高代码的运行速度。我认为严格模式代表了 js 一种更合理、更安全、更严谨的发展方向。